Transcription App
A web app for automatic speech recognition using OpenAI's Whisper model running locally.
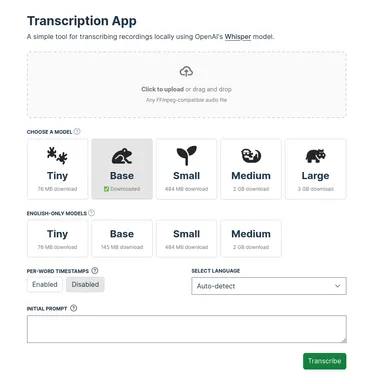
Features
- Customize the model, language, and initial prompt
- Enable per-word timestamps (visible in downloaded JSON output)
- Runs Whisper locally
- Pre-packaged into a single Docker image
- View timestamped transcripts in the app
- Download transcripts in plain text, VTT, SRT, TSV, or JSON formats
Architecture
The frontend is built with Svelte and builds to static HTML, CSS, and JS.
The backend is built with FastAPI. The main endpoint, /transcribe, pipes an uploaded file into ffmpeg, then into Whisper. Once transcription is complete, it’s returned as a JSON payload.
In a containerized environment, the static assets from the frontend build are served by the same FastAPI (Uvicorn) server that handles transcription.
Run with Docker
Run and attach to the container:
docker run --rm -it -p 8000:8000 -v whisper_models:/root/.cache/whisper ghcr.io/fluxcapacitor2/whisper-asr-webapp:mainRun in the background:
docker run -d -p 8000:8000 -v whisper_models:/root/.cache/whisper ghcr.io/fluxcapacitor2/whisper-asr-webapp:mainAfter starting the Docker container, visit http://localhost:8000 in a web browser to get started.